Agents Reason.
Sertainly Decides.
AI agents are probabilistic. Business decisions must be deterministic. Sertainly gives your agents versioned decision APIs they call via REST or MCP — sub-millisecond decisions, full trace, zero inference at runtime.
No SDK required · Any agent framework · Curl-compatible
Why agents need a deterministic decision layer
LLMs reason probabilistically. When your agent needs to approve, deny, route, or escalate — probabilities aren't good enough. Sertainly is the deterministic layer between your agent and the real world.
Determinism
Same case + same rules version = identical decision, every single time. No model variability. No prompt drift. No “it said yes yesterday and no today.” Version-pin a decision package and your agent's decision logic is locked until you explicitly promote a new version.
Pin artifacts per environment:expense_policy@2.1.0 in prod, @2.2.0-rc1 in staging.Observability
Every decision comes with a trace_id, fired-rule list, computed facts, and citations back to the source document. Debug “why did the agent do that?” with evidence — not by replaying prompts and hoping the model behaves the same way twice.
Speed
Sertainly evaluates compiled rules IR — no embedding search, no retrieval, no LLM inference at decision time. Evaluations run in sub-millisecond time, making Sertainly suitable for high-volume, real-time agentic workflows where RAG latency would be a showstopper.
RAG: 500ms–3s per decision. Sertainly: <1ms. At 10,000 decisions/day, that's hours of agent wait time eliminated.Cost
Sertainly uses AI once — at compile time — to extract rules and generate the artifact. After that, evaluations are pure computation: no tokens, no inference, no per-decision AI bill. The cost model is flat and predictable.
AI is used once at compile time, not on every runtime evaluation. Cost per decision approaches zero at scale.Prompt-based guardrails are probabilistic. Policy-based guardrails are deterministic.
RAG is powerful for research and guidance. But when your agent needs to make an authoritative decision — approve or deny, route or escalate — you need rules enforced outside the prompt, not inside it.
RAG approach
- Non-deterministic: same question, different answers across runs, model versions, or document ranking changes
- Expensive per decision: embedding search + retrieval + LLM inference on every call — cost scales linearly with volume
- Slow: retrieval latency + inference latency on every evaluation — 500ms to 3s per decision
- Audit black box: “why” requires reconstructing model behavior from logs — not reproducible
- Silent rules drift: document or embedding changes silently alter decisions without an explicit version bump
- Fills gaps with confidence: missing data is guessed, not surfaced — your agent acts on invented facts
Sertainly approach
- Deterministic: same case + same rules version = identical decision, always — no model variability
- Near-zero cost per decision: compiled IR, no embedding search, no inference at evaluation time
- Sub-millisecond: single REST call, no retrieval pipeline, no LLM invocation at decision time
- First-class trace: every decision links to fired rules, source citations, and a replay token
- Explicit versioning: rules changes create new pinnable versions; rollback is instant
- Structured missing data: the engine halts with
evidence_needed[]when fields are absent — no hallucinated gap-filling
The difference isn't just conceptual — it affects latency, cost, determinism, and auditability at runtime.
| Dimension | RAG / Runtime AI | Sertainly |
|---|---|---|
| Determinism | Low–Medium | High |
| Per-decision cost | Scales with tokens + retrieval | Near-zero (compiled IR) |
| Latency | ~500ms–3s (retrieval + inference) | Sub-millisecond evaluation |
| Missing data | Fills gaps — silently, confidently | halts with evidence_needed[] |
| Auditability | Reconstruct from logs | First-class trace + source citations |
| Rules versioning | Implicit (doc change = silent drift) | Semver, pinnable per environment |
| AI at runtime | Every call — retrieval + inference | None — AI used only at compile time |
| Best for | Advice, exploration, guidance | Authoritative enforcement |
The winning pattern: use an LLM for natural language understanding and planning, then call Sertainly for the authoritative decision. LLMs reason; Sertainly decides.
halted One more thing RAG can't do: tell you what it's missing
Sertainly makes missing information a first-class outcome. When a require rule's evidence is absent, the engine halts execution and returns halted with an explicit evidence_needed[] array. Your agent loops back, asks the user exactly the right questions, and re-evaluates. No guessing. No hallucinated field values. Guaranteed termination because the schema is finite.
Rules (YAML) — require rule
Agent loop (pseudo-code)
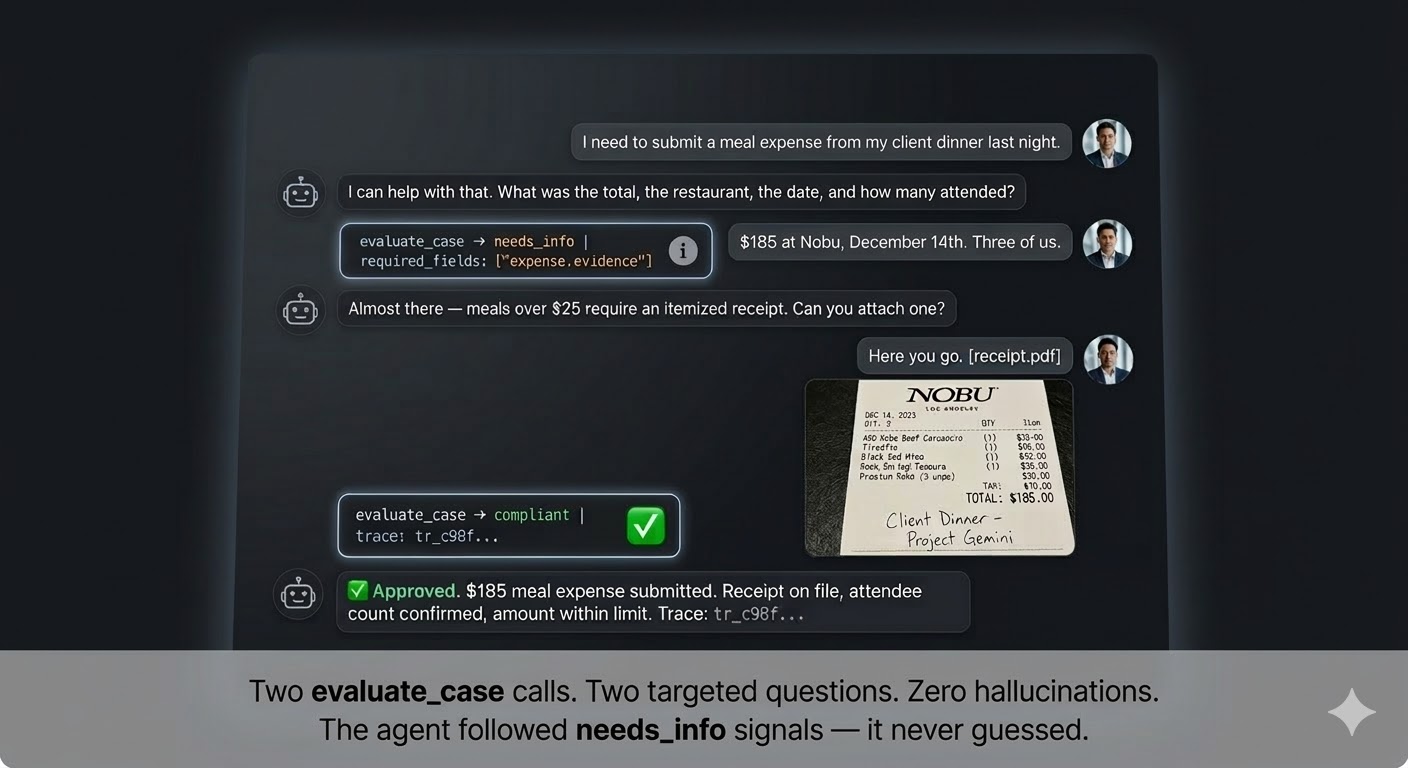
See it live: a Sertainly-powered expense agent
A real agent conversation powered by Sertainly. The agent uses the halted + evidence_needed channel to collect only what's required, then returns a deterministic decision. No hallucinations. No over-asking.
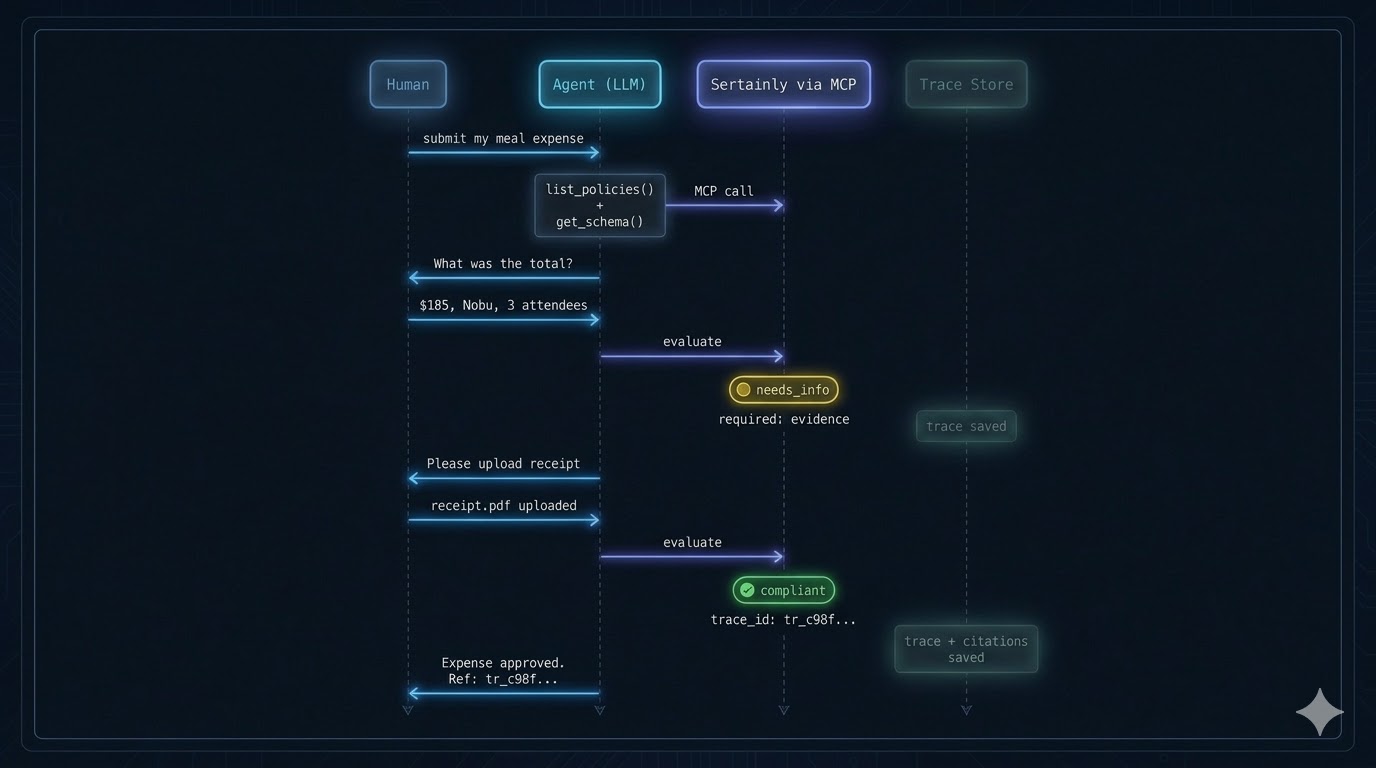
Your agent calls decisions as MCP tools
Sertainly exposes four MCP tools: list_policies, get_schema, evaluate_case, and get_trace. Your agent discovers and calls them natively — no custom integration code.
list_policies
Discover available rules, versions, and effective dates. Agent uses this to select the correct rules to evaluate against.
Input: none · Output: [{package_id, version, effective}]get_schema
Returns JSON Schema for the case — what fields are required, their types, and allowed enums. Drives the agent's question generation.
Input: package_id, version · Output: JSON Schemaevaluate_case
Submit the case. Returns status (ok / halted / failed / invalid), channel-shaped outputs, and a trace_id. The core decision call.
Input: case, package_id · Output: status, outputs, trace_idget_trace
Retrieve the full audit trail for any evaluation. Returns the applied rules, computed facts, candidate resolution per channel, and source citations.
Input: trace_id · Output: applied_rules[], facts, trace_detail.candidatesDeterministic agent-to-agent handoffs with ROUTE
Multi-agent systems need more than routing logic written in LLM prompts — they need routing logic that is versioned, auditable, and identical across every run. The route rule kind emits a destination into outputs.routes[]. Your orchestrator reads that destination and hands the case to the right specialist agent — deterministically, every time.
Sertainly Rules route rules (YAML)
- Routes accumulate into
outputs.routes[]— downstream consumers see every destination that fired sla_hourstravels with each route entry for downstream SLA tracking- Conflict-resolution strategies in the package's tag/route sets pick a winner when multiple routes fire
Orchestrator Reading the route destination
- No prompt-based routing — the rules decide, not the LLM
- The receiving agent gets the full trace: what triggered the route and why
- Routing logic is versioned with the rules — update routing rules without touching orchestrator code
Why not just prompt-route?
When routing is in an LLM prompt, the routing logic changes every time the prompt changes — silently, without a version bump. With ROUTE statements in Sertainly, routing logic is part of the decision package. It's versioned, testable, and replayable. Promoting a new rules version is the only way routing logic changes.
Use for: compliance triage, approval chains, specialist escalation, human-in-the-loop gates.Trace continuity across agents
Every routed evaluation carries a trace_id that the receiving agent can pass to get_trace. The specialist agent sees exactly which route rule fired, what data triggered it, and the full case at the moment of handoff — no context reconstruction required.
The four statuses — and what to do with each
Every evaluate_case call returns six independent channels plus a derived status. Status is a first-class signal your agent can act on deterministically — not a probability score to interpret, but a structured instruction to follow.
ok Case is valid, execution succeeded
Read outputs.tags, outputs.routes, and outputs.facts to see what the rules emitted. The agent acts on the channel-shaped decision.
halted A require rule stopped execution
The engine cannot proceed without evidence the policy demands. outputs.evidence_needed[] tells the agent exactly what to ask for.
failed Execution failed
An engine error, FEEL exception, or output-contract violation aborted the run. execution.errors[] carries the cause.
invalid Case input failed schema validation
The case object didn't match the package's input schema. case_validity.missing_fields[] and case_validity.errors[] point at the problem.
routes Channel-shaped handoff
route rules add destinations into outputs.routes[] alongside any tags. Status stays ok; routes are how the agent hands off downstream.
outputs.routes[] and dispatch to the named specialist or human queue.Quickstart: evaluate your first case in 5 minutes
No SDK required. Sertainly is a REST API — if you can curl, you can integrate. Here's the complete flow from zero to decision.
Don't want to write rules by hand? Upload a source document and let AI extract, compile, and test the decision package for you. You review and approve — then everything below applies.
Get your API key
Create a free account. Copy your API key from Settings → API Keys. No credit card required.
Discover available rules
Call list_policies to see what's available. Returns policy IDs, versions, and effective dates.
Fetch the schema (know what to collect)
Before sending a case, get the schema to understand what fields are required. This is what drives agent question generation.
Evaluate a case
Send the case. You'll get a status, channel-shaped outputs, and a trace ID. If the status is halted, outputs.evidence_needed[] tells you exactly what's missing.
Handle halted in your agent loop
When evidence is missing, Sertainly returns status: "halted" with an outputs.evidence_needed[] array. Loop back, collect the missing data, and re-evaluate.
- Loop terminates because evidence requirements are finite and schema-bounded
- Each partial call returns a trace_id — full audit trail even for incomplete attempts
- Each evidence entry carries its own
reason_codeso the agent can phrase the question precisely
Fetch the trace (optional, for audit or debug)
Every evaluation produces a trace. Use the trace_id to retrieve the applied rules, computed facts, candidate resolution per channel, and source citations.
Add it to your MCP server (optional)
Expose list_policies, get_schema, evaluate_case, and get_trace as tools in your MCP server. Your LLM agent can discover and call them natively — no custom orchestration code needed.
- Works with Claude, GPT-4o, Gemini — any MCP-compatible agent
- Agent reads the tool description to understand when and how to call it
- Chain multiple rule sets: eligibility → pricing → approval in one agent turn
Agent workflow patterns
Patterns builders are shipping today. Each is enabled by deterministic decisions — not possible with prompt-based guardrails alone.
Iterative Case Completion
Agent loops on status: "halted" until all required evidence is present, then gets a final decision. Guaranteed termination. Zero hallucinated field values. Works over multi-turn chat, voice, or async forms.
outputs.evidence_needed[]Deterministic Action Gates
Agent proposes an action (refund, approval, write operation). Sertainly evaluates before anything is executed. The emitted tag set tells the agent whether to proceed, block, or hand off — not a probabilistic “probably no.”
Key signal:outputs.tags + outputs.reason_codesRisk-Based Routing
Low-risk cases (tags: ["compliant"]) proceed autonomously. Medium-risk fires a route rule that drops a human-queue destination into outputs.routes[]. High-risk classify rules emit a non_compliant tag and your orchestrator blocks. One set of rules, three lanes.
route → outputs.routes with to: APPROVAL_QUEUERules-as-Contract Testing
Write test cases as JSON. Replay them against new rules versions before promoting to production. Diff channel outputs across versions to catch behavior changes — not in prod, in CI.
Key tool:get_trace · replay token on every decisionPlans
Decisions are billed per evaluation. AI features use separate credits. Start free, scale when you need to.
Free
Build and test on shared infrastructure. No credit card required.
10,000 decisions / month
- 1 decision package
- Shared runtime
- CLI + REST + MCP
- 7-day trace retention
- 200 AI credits / month
- Community support
Professional
For teams shipping agentic workloads in production.
250,000 decisions / month
- Unlimited packages
- Dev / Staging / Prod environments
- Team access + CI publish tokens
- 30-day trace retention
- Replay + export
- 500 AI credits / month
- Email support
Enterprise
Governance, certified builds, and private runtime for mission-critical agents.
Custom decision volume
- Dedicated / private runtime
- Governance workflows + certified builds
- Signed artifacts + audit export
- SSO / RBAC
- Custom retention + VPC / on-prem
- Included AI build capacity
- SLA + priority support
Agents reason. Sertainly decides.
Give your agents deterministic guardrails they call as tools. No prompt engineering. No inference at runtime.